AI whiplash, and neovim in the age of AI
When I was getting started with incorporating AI assistants into my coding workflow, I experienced this feeling of thrash / jerk. I started vibing. I was running prompts. Things were happening, but then the agent ran into a wall.
Suddenly I realize it's been going off the rails for a little while. I have to stop and backtrack and make sense of the mess that the AI has made. I try fruitlessly to re-prompt the agent to keep going, to get back that feeling of effortless progress. After a few minutes of tweaking prompts I give up and reset to the last checkpoint.
As this sensation of ease and speed disappears, it feels really bad. You end up wondering if you would have gotten things done faster by just ignoring the AI altogether. I think of this feeling as "AI whiplash".
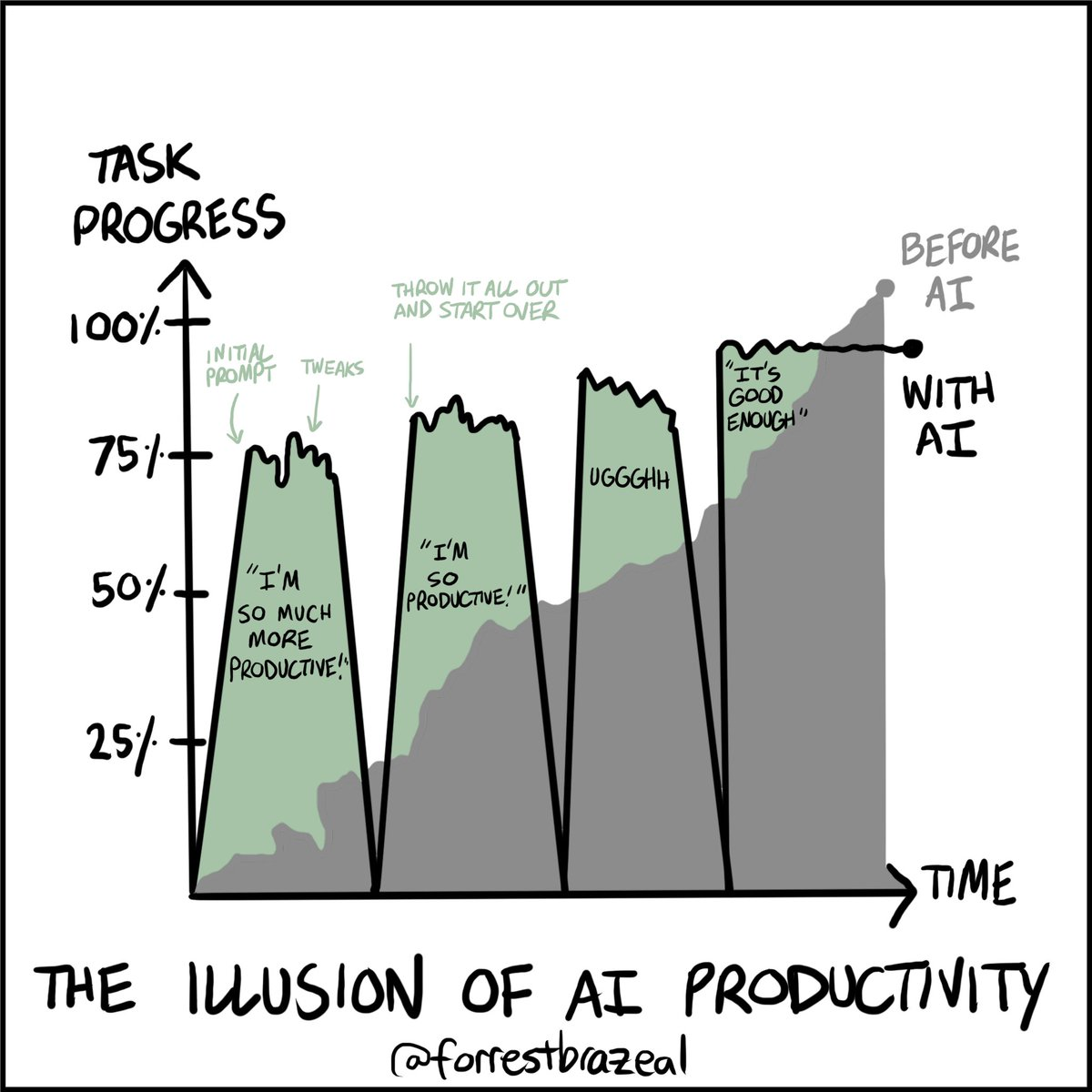
It seems I’m not the only one who has observed AI whiplash. From https://x.com/forrestbrazeal/status/1861809466355732670
metr
I found myself reflecting on this while reading the much-circulated METR study of the effects of AI on developer productivity.
METR recruited 16 experienced developers who regularly contribute to large open-source repositories. These devs had an average of five years and 1,500 commits of experience.
Developers provided lists of real issues (246 total) that would be valuable to the repository: bug fixes, features, and refactors that would normally be part of their regular work. Then, researchers randomly assigned each issue to either allow or disallow use of AI while working on the issue.
The developers had mixed experience levels with AI coding tools. Only 56% of the developers in the study had experience using Cursor, the main AI tool offered in the study. While nearly all the developers (94%) had experience using some web-based LLMs in their coding workflows, this study was the first time about half used Cursor specifically.
When developers were allowed to use AI tools, they took 19% longer to complete issues. Even more striking was the perception gap: developers anticipated that AI would speed them up by 24%, and even after performing the task, they still (erroneously) believed AI had made them faster by 20%.
The results varied significantly across developers. A quarter of the participants saw increased performance, 3/4 saw reduced performance. Notably, one of the top performers for the AI condition was also someone with the most previous Cursor experience.
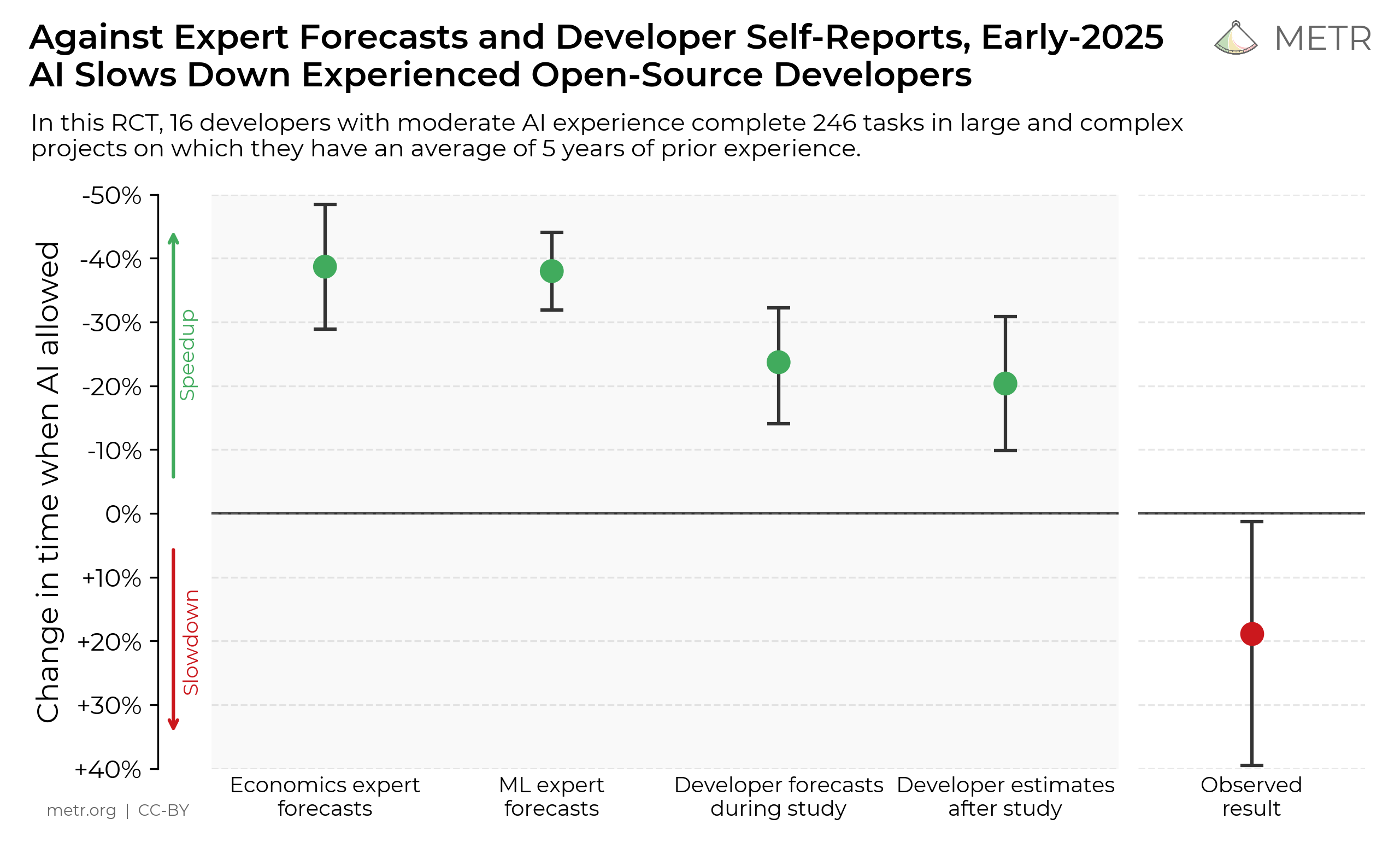
A nice little fuck-you to the AI productivity boosters from the paper.
I think this study effectively challenges the narrative that AI provides instant improvements in developer productivity of up to 40%. This study shows that productivity gains from AI (on this sort of high-context, in-depth work) are not so easily obtained. AI coding assistants are a tool. Like any tool there's a learning curve, and it's likely that developers will be less productive when they begin to incorporate this new tool into their workflow.
As an aside, I think this study did an excellent job (when compared to other AI discourse) of capturing what experienced software engineers' tasks actually look like. Even so, it is only measuring a shallow definition of productivity. Speed in implementing concrete tasks doesn't capture the process of selecting the tasks. It is the skill and taste involved in navigating the problem/solution space that makes or breaks software engineers, and we are not measuring that here.
(Also, can we stop talking about the SWE workbench benchmark? It really doesn't mean anything. Also also, it really bugs me when tech thought leaders opine that "90% of the code is written by AI". What does that even mean? Like 90% of the characters in the file? Prior to AI, what % of the code was written by autocomplete? What % was copy-pasted from google / stackoverflow? Stuff like this should permanently disqualify you from being taken seriously ever again.)
gradient of control
When a friend was recounting an experience with AI whiplash recently, I realized that I hadn't felt this feeling in a little while.
I now have a much better sense of when the AI agent might be successful or not successful at a task, and how much scaffolding it needs to have a decent chance of success. I know when I can just let it run, and when I need to slow down and carefully examine its work, or step in to hand-code things myself. The initial illusion of AI speed, and the corresponding feeling of whiplash, has faded.
What I see myself doing now is traveling along a gradient of control.
One example of this is the plan -> execute workflow. You start by having the agent come up with a plan for implementation, which you exercise a high degree of control over. I think reviewing a plan effectively requires a strong sense of what the agent will be able to do. As I've gotten better at reviewing and improving plans, I often hand-edit the steps, specify as with pseudo code and generally make the steps as concrete and unambiguous as possible. After that, I can step back and cede control to the agent, which does a pretty decent job at well-specified tasks.
Another example of traversing the gradient of control is a workflow I've adopted during refactoring:
refactor one file manually or with a lot of supervision
tell the agent to "save what you learned to
refactor.md"try and apply these refactor instructions to a second file
review and manually correct the agent
tell the agent to update the refactor file with what it learned
repeat until the agent can perform a refactor adequately close to correct
then get the agent to apply the refactor to the remaining files Using this flow, this 20K-line refactor in one of my other projects, porting from react/immer/tea to a more simple framework, took only a couple hours.
Here again there's a smooth transition from high-touch developer-driven work, to low-touch agent-driven work as the context becomes more concrete and the tasks better defined and predictable.
magenta.nvim - an AI coding assistant for neovim
For the last 8 months, I've been developing an AI plugin for neovim: magenta.nvim. This has allowed me to explore and gradually organize some thoughts on how AI tooling should facilitate developers' interactions with the agent.
___ ___
/' __` __`\
/\ \/\ \/\ \
\ \_\ \_\ \_\
\/_/\/_/\/_/
magenta is for agentic flow(btw, I really want to commission an ascii art logo for this project. Something like a cursive m in a cyber-punk / glitchy style. Please get in touch with me with some examples of your work).
automatic context
AI tooling should tell the agent what time it is, what language the user likely speaks, what project they have open and its location on disk, what buffers the developer has visible to them, the status of version control, etc...
One powerful feature I built for magenta in this category was buffer tracking. Once you add a file to magenta's context, or the agent reads the file on its own, magenta will keep track of the agents' view of the buffer. Whenever the buffer changes, it will automatically send the diff of the change to the agent. This opens up a really nice workflow where you can pause the agent, manually edit some files, and then just say "here's how to do it", and have the agent directly observe the diff of your edits.
We can also automatically detect context files. This lets you persist documentation, coding conventions and similar things in a context.md file. At the end of my threads, I often say "take what you learned from this interaction and save it in the context.md file", which gradually improves this file.
Another feature in this category (also supported by magenta) is edit prediction, where the plugin observes your edits as you explore and modify your code base, and the user can use that context to ask the agent to infer the next edit.
Automatic context can be a double-edged sword since it can distract the agent. For example, early versions of the system prompt would cause magenta to interpret all queries in the context of the current project. This is pretty frustrating when you're just trying to gather some general info about a library that's not yet part of your project.
I'm really curious about ways in which one can use the state of the IDE to conditionally provide additional pieces of context to the agent. Can new prompts be triggered by files you are working with, some key words in your prompt or visible buffers, or your recent activity? This may be a way to improve the agents' performance while avoiding the distraction issue.
An extension of this idea I'm really curious about is supervisor agents. This would be an agent that periodically reads over things that a worker agent is doing, and can send reminders to the worker agent, or provide it with additional context or prompts as needed. I'm thinking things like “I see you’re working on a view file in the client directory - here’s info about our view framework”, "remember, make sure to check for type errors before you attempt to run tests", or "rather than doing web searches to find library documentation, try exploring the node_modules directory".
I think this sort of prompting technique could be an interesting way to provide a much higher degree of context to the worker without distracting it. It could also help keep the worker on-track, as supervisor messages would be recent within its context window.
manual context
It should be really easy for the developer to add context to the agent. Here are a few ways that the developer can send context to the agent via magenta:
adding files. This can be done either by opening the file and using the
<leader>mbto add the current buffer, or using<leader>mfand using the fuzzy picker. (I also want to add the ability to @-mention a file while composing a message in the input buffer).adding snippets. You can visually select a snippet and use
<leader>mpto paste it into the input buffer. It also captures the file path when it does so.<leader>miallows you to provide an inline edit prompt, which attaches the contents of the buffer, and the position of your cursor to the context. If done while something is selected, this forces the agent to replace the selection.@quickfix,@diagnosticsand@bufferscommands. These allow the user to quickly gather things that they see in their IDE and send them to the agent.@diff:filepathsends the version-control diff of the file to the agent. This is a much quicker instruction than telling the agent “check the diff of the changes I have so far” and having it use the bash tool to do so. Generally, I'm trying to be mindful of situations where I'm struggling to communicate something about my project's context to the agent - these are all opportunities to improve on this category.
focus and context retention tools
Agents struggle with ambiguous prompts, or prompts that mix multiple objectives. Agents also tend to lose track of what they're doing as the context window grows above 100K tokens or so. An IDE should also give you lots of flexible tools for pruning, reusing your context.
The @fork feature was one I developed early and now use constantly. When you prefix a prompt with @fork, magenta first asks the agent to extract pieces of the current context that are relevant to this future conversation direction. Magenta then creates a new thread with that distilled context, and automatically sends off your prompt into the new thread. It's a really great way to retain some of your hard-earned context as you move on to new tasks.
Managing context focus is where workflows around planning and sub-tasking really come into play. The idea is to compose a plan, and then use sub-agents to complete each individual task using a focused, dedicated context window. Magenta supports this very flexibly via the spawn_subagent and wait_for_subagents tools.
There's also the spawn_foreach tool, which lets the agent run multiple sub-agents in parallel - each with a shared base prompt plus their own specific task. This is particularly useful for repetitive operations like refactoring multiple files, where the base prompt might contain instructions for how to do the refactor, and the task array would contain the list of file names where this refactor would need to be applied.
Again, here redundancy and flexibility are key. Another way magenta allows for context reuse is through the inline-edit feature. Not only does this attach the context from the active thread, it also saves the last inline prompt so you can easily replay it against new files and selections by using <leader>m..
neovim in the age of AI
There was recently a post in the r/neovim community: Are we the dying tribe of craftsmen in the industrial revolution of AI?. It raises a concern - is neovim obsolete in the age of AI?
Based on my experiences developing this plugin, and also using it extensively on my side projects and my day job, I think quite the opposite: neovim remains extremely relevant in the age of AI.
at the speed of thought
The foundation of modal editing is that the majority of a developer's time is spent navigating, reading and modifying code. This is even more true in an AI-enabled workflow. You don't have to get distracted by pointy-clicking your way through awkward UI when you need to make an adjustment to your prompt, revise the agent's changes, gather some context, or hand-code a key piece of the implementation. With your hard-earned neovim muscle memory, you can do this all while staying focused on the problem at hand.
transparent and malleable
No two developer's neovim setups are the same - that is part of the beauty of the tool. Vim users mold their environment to their particular preferences and workflows over years of editing their configs (there is no beauty without pain). This allows the tool to get out of your way (since you can configure it just-so), and also to automate the various personal pain points you might encounter in your particular tech stack.
The current wave of LLM models greatly benefit from being tuned to specific problems and use cases. Because of this, I think that having an open-source, transparent coding assistant integrated into a customizable environment like neovim raises the ceiling for what is possible to automate with AI. You can see all of the prompts and tool specifications that magenta uses to achieve its behavior. You can fork the repo and adjust them to your own use cases. (I’m also thinking about how to make these more configurable). As described above, magenta offers a variety of redundant ways of accomplishing the same tasks, so that developers can pick and choose the way that feels most intuitive to them and is most effective for their workflow.
Within neovim, AI becomes another tool in a flexible and composable toolbox you can bring to bear on your daily toil.
amusements
Part of the point of this blog is to give myself permission to go on various tangents.
I often think about this video from jazz musician and youtuber Adam Neely reviewing the movie Whiplash. (The "whiplash" tie-in was not intentional!) Adam observes that the movie misses an extremely important part of the jazz culture - musicians think that music is really fun.
I grew up on Snow Crash, Neuromancer, Cryptonomicon, Ghost in the Shell and the Matrix — trying to code up small games, getting excited about gadgets, scifi and web obscura. Coding being fun is something that is dear to my heart. I find this culture difficult to find in the venture-capitalist fascist hellscape that tech has become (crypto, fintech, adtech, ai slop, etc...).
The first time I saw someone zipping around in vim was an awe-inspiring moment for me. Just a few months ago, I got to be that inspiration for an intern that I paired with briefly. A few months later, when he returned to start a full-time position at my company, he told me that he got hooked on neovim after watching me.
I think neovim has absolutely made me a more productive developer over the last 20 years, but more importantly, neovim is just cool. So magenta has been a labor of love - it’s a privilege to help keep neovim relevant for the next generation of people who love tech.